How we use hermetic, ephemeral test environments at Google to reduce flakiness
The complexity behind eradicating test flakiness, Part 2
If Medium puts this content behind a paywall, you can also view it here (LinkedIn)

A couple of weeks ago, I published “When sharks chew on network cables — The complexity behind eradicating test flakiness.” In that article, I explored the common sources of flakiness in Integration Testing. There’s a surprising amount of complexity in the domain, like unreliable dependencies, unreliable network connections, and test instantiation and test cleanup problems with system state. This is Part 2 to that.
I’m in the org that owns the Developer Infrastructure for Integration Testing at Google, so this is very dear to my heart. We run millions of integration tests every single day, so this flakiness presents itself often simply by virtue of scale. Throughout the years, we have invested in a significant amount of engineering productivity infrastructure to reduce, mitigate, and in some cases eradicate some of these problems. One of those interesting pieces of infra is ephemeral, hermetic test environments.
Googlers love Three Letter Acronyms, so rather than saying “test environment” all the time, we use the term “SUT” (which stands for “System Under Test”). By this I mean: an instance of the server or pipeline that contains the changes you’re intending to test, so that you can run your integration tests against it.
“Hermetic” and “Ephemeral” are pretty fancy words, so let’s dissect them, and see what properties each one brings to the table.
What’s “Ephemeral”?

Ephemeral means that the SUT gets spawned on demand, before the test runs, and it gets torn down at the end of the run.
This is in contrast to the more traditional static, long-lived, shared test environments that companies like Amazon use (prior to Google I worked for many years at Amazon’s Developer Tools organization, also focusing on integration testing problems there). With ephemeral environments, each run gets its own instance of the SUT.
Ephemeral SUTs bring some nice qualities. The problems of state, data seeding, test concurrency and test cleanup that I pointed out in Part 1 now go away, since each test run has a dedicated SUT and it’s impossible for them to step on each other’s toes. Data seeding becomes a first-class citizen of the SUT creation process: the infrastructure stands up the SUT, seeds the data into it, and then, and only then, do your tests run.

What’s “Hermetic”?

Hermetic means that we spawn not just your SUT, but also all of its dependencies, into a single container, removing inter-system network calls.
This is in contrast to the more traditional environments that make network calls to Production or Staging stacks of their dependencies.
Hermetic SUTs bring some nice qualities. The problems of flaky dependencies, sharks eating your fiber, network latency and network flakiness that I pointed out in in Part 1 now go away (mostly). I say mostly because you could still be standing a flaky version of a dependency. But instead of depending on a shared staging environment of your dependency, which may have experimental, untested code deployed to it, you can be standing your own version of your dependency from a blessed, well-tested version of it, so it’ll likely be much more reliable.
You go from this:

To this:
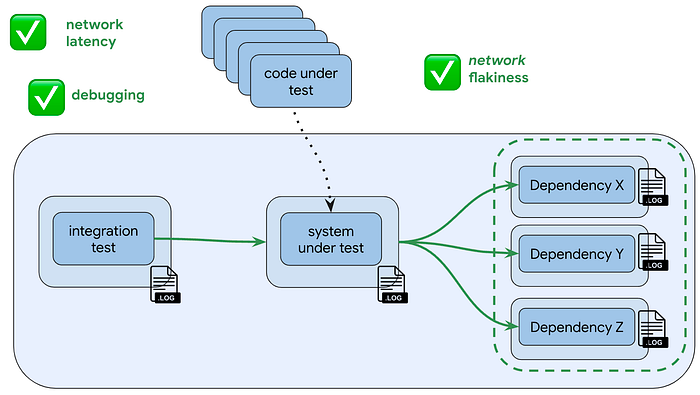
There are other benefits. Your tests are now reproducible. In the world where your tests can fail because of flakiness in a dependency, you’ll often experience the problem that the dependency releases a new version between the time you originally ran your test and the time you try to reproduce the problem, and those changes no longer create the situation that exhibited the problem. And debuggability is also better now, because dependencies do not have to be black boxes any more: you stand up a stack of your dependency, you can access its log files, you can inspect its database, etc.
So, this fixes all the problems, right?

No. All the benefits of hermetic, ephemeral test environments are great, but this does not mean that you shouldn’t test on more traditional, larger, distributed environments. You very much still should. But it does allow you to shift-left a lot of the tests and run them in cheaper, faster, more reliable environments, yielding earlier problem discovery, and a more trustworthy signal from these tests.
My second disclaimer is that while Ephemeral, Hermetic environments solve a lot of problems, they bring their own set of problems.
That’s right. There are problems from the solution to the problem. There’s some irony there isn’t it? But this is Google so we also came up with solutions to the problems from the solution to the problem. Of course, those brought their own problems as well, so we had to come up with solutions to the problems to the solutions to the problems from the solution to the problem.
Problems from the Solution to the Problem
- The first problem is that your tests take much longer to start up. In more traditional long-lived staging environments, the SUT is up 24x7, sitting there just waiting for your test to run against it. But in the world of ephemeral test environments, the infrastructure needs to start up your SUT every single time, before your tests can run. This often means building and deploying code, starting up the service, and data seeding it. How long this takes depends on many factors: whether you’re starting an SUT on your local machine, or in a data center, how many dependencies and transitive dependencies it needs to bootstrap, how much data it needs to seed, etc.
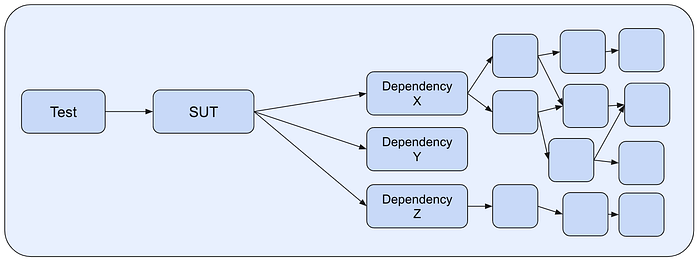
- The second problem you’ll likely encounter is that your SUT may be too big to actually fit in a box (to honor hermeticism). If you truly want or need stacks of your dependencies and transitive dependencies, that dependency graph can explode quite quickly.
What about SUT startup taking too long?
We’ve taken a multi pronged approach to the test startup problem, because Google is a very complex ecosystem and what is an appropriate solution for one team may not be the right solution for another team.
- First, we’ve focused on optimizing boot time on the infrastructure that is responsible for starting and shutting down the SUTs, with things like caching and smarter parallelism, to improve latency for everybody. Our infrastructure starts millions of these SUTs every single day, so even shaving off a few seconds for each adds up to a good amount of savings at Google scale. The downside is that there’s only so many global optimizations you can make, and sometimes you need to deeply understand the idiosyncrasies of each specific SUT to optimize it further.
- Secondly, and to address the downside I just mentioned, we invested in creating telemetry and dashboards so that service owners can dive deep and identify bottlenecks in their specific SUTs. For example, if your SUT takes 10 minutes to start, and you realize one of your dependencies is consuming 8 minutes, then you’ve identified the long-pole in the process. You can choose to replace your dependency with a much faster mock, or convince those engineers to improve the boot time of their component. Having data, to make data-driven decisions, is paramount. The downside here is that diving deep into timing information for each component in a complex SUT is quite time consuming from an engineering perspective.
- Third, we have infrastructure that manages pools of pre-started SUTs so that tests can lease them for immediate use. This doesn’t eliminate the startup time, but it hides it: as far as your tests are concerned, when they need an SUT, they get it immediately. As soon as an SUT is leased to a test, our infrastructure removes it from the warm pool and starts another one, so that at any given moment there’s several SUTs immediately available. The downside here is that you’re incurring in additional cost to achieve that speed. But for some teams that are working on highly innovative projects that need very fast iteration, it comes down to a business tradeoff: achieve higher delivery speed at additional hardware cost.
- Fourth, our infrastructure also has the ability to reuse a preexisting SUT. This is mostly used in local development where engineers are iterating quickly: small change, deploy, test, repeat. We also can take advantage of things like Java hotswap to rebuild and redeploy just a part of the system when a change is detected instead of the entire system. The downside is that this violates the ephemeral property that I told you was so important. This comes down to being pragmatic about when to relax some of the rules to achieve a reasonable business outcome. You’re not reusing a long-lived shared environment where you don’t control what test used it before yours and in what state it left it, you’re reusing an environment that you fully own, so there’s a smaller risk.
What if your SUT doesn’t fit in a box?
Some of the SUTs we spawn are huge. Imagine fitting gmail, google search, maps, docs or youtube in a box? At some point, it becomes impossible to neatly fit a system and all its dependencies in a single hermetic box.
Like in the previous case, we’ve taken a multi pronged approach to this problem, as what is an appropriate solution for one team may not be the right solution for another team in this case too.
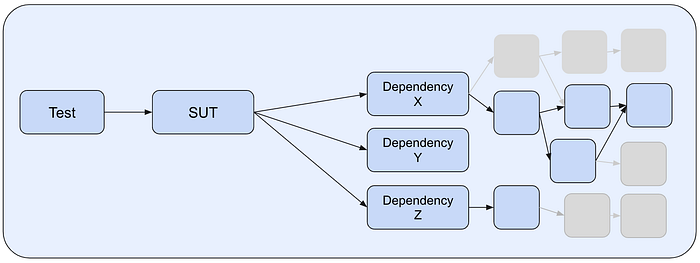
- First, we have infra for pruning unused dependencies (particularly unused transitive dependencies). Dependency X may call System ABC in some cases, but perhaps not for the test cases you’re executing. We can spy on intra-system calls at runtime to prune your SUT. The downside is the only way to really know which dependencies are used is at runtime, and this can change over time. Imagine you prune your dependencies, and after that you add a test case that triggers a call to a dependency that you just pruned.
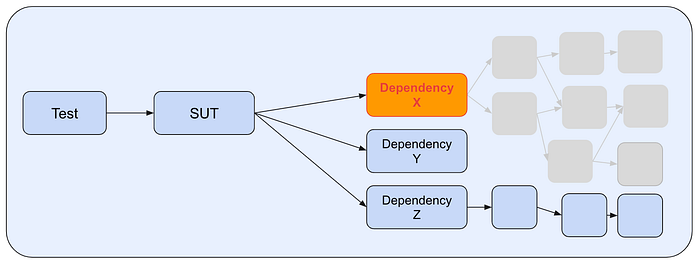
- Secondly, we can choose to replace a dependency with a fake, mock, stub, or even a network call to a staging stack of your dependency. This too has downsides. By using a fake/mock/stub, you’re likely reducing fidelity, as it’s extremely hard to ensure it behaves exactly as the real deal. Even if you painstakingly make sure it’s prod-realistic today, how can you ensure it’ll be prod-realistic tomorrow? The other option, making network calls to a staging stack of your dependency, breaks hermeticism. I don’t love this, but I tend to be more pragmatic than dogmatic and I want engineers to have the freedom to make these tradeoffs deliberately. It may be the case that for what you’re trying to do, breaking hermeticism or reducing fidelity for that one dependency so that you can keep hermeticism and fidelity for the rest of your SUT is a reasonable tradeoff.
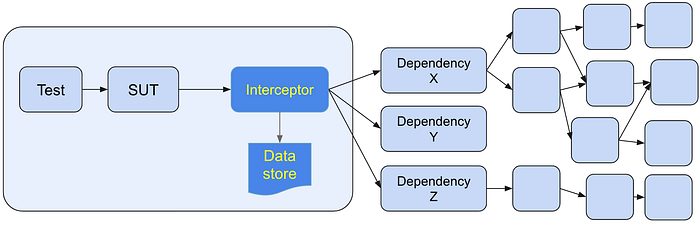
- Thirdly, another option is Record-Replay. In Record Mode, your dependencies can live anywhere, so you’re not bound by the hardware limits of a single box. The infra discreetly and automatically adds a little interceptor, which records all the requests and replies from all these dependencies to a datastore (they can be at any level of your runtime closure). Once you’ve recorded the interactions between components, you no longer need them to be present in your SUT, you can simply replay them from the datastore. Record-Replay does have cons. Dealing with non-determinism is extremely difficult. Let’s say a response from a system is bound by randomness, or it’s a function of the time, so calling with the same request can generate different responses. The other bit of complexity is when to refresh your recorded logs. When do you record? Once a day? Once a week? Every N times? Does it happen automatically or manually? Does it happen when the test runs or does it happen asynchronously (which requires additional infra). Despite all the cons, record-replay does allow you to have hermeticism and reproducibility in situations where it would otherwise be impossible.
Did we eradicate test flakiness?
No. But I do strongly believe that using hermetic, ephemeral environments has significantly improved test flakiness across the entire company.
It was not a cheap endeavor. Generations of engineers before me have built massive amounts of infrastructure to support this at google-scale. They came up with solutions to problems, then they came up with solutions to problems to solutions to problems.
In my first article, I explained to you why the space is complex. In this second article, I explained to you why the infrastructure to deal with the space is complex.
In the end, it all comes down to tradeoffs.
